Nodejs爬虫实践小记
Nodejs将前端开发语言移植到服务器端,如今一个前端开发者使用Nodejs很容易就能实现一个网络爬虫,这在之前是不可想象的,本文介绍一个简单的Nodejs爬虫的开发过程,只想看代码的直接拉到最后。
爬取原理
- 首先爬虫程序要发起http请求得到页面HTML,进而获取到你希望得到的信息,例如正文或图片
- 然后爬虫要捕获页面间的链接关系,通常是”上一篇下一篇”这种外链
- 通过外链继续重复第一步,从而实现自动化抓取,这里注意需要给程序设定一个退出边界,比如当找不到下一篇的时候,或者总抓取次数达到多少的时候,防止陷入死循环
目标分析
本次抓取目标选择的是cnBeta.com,观察发现cnBeta的新闻详细页包含相邻页面的链接,但是通过查看源代码发现,这个链接是Js生成的:
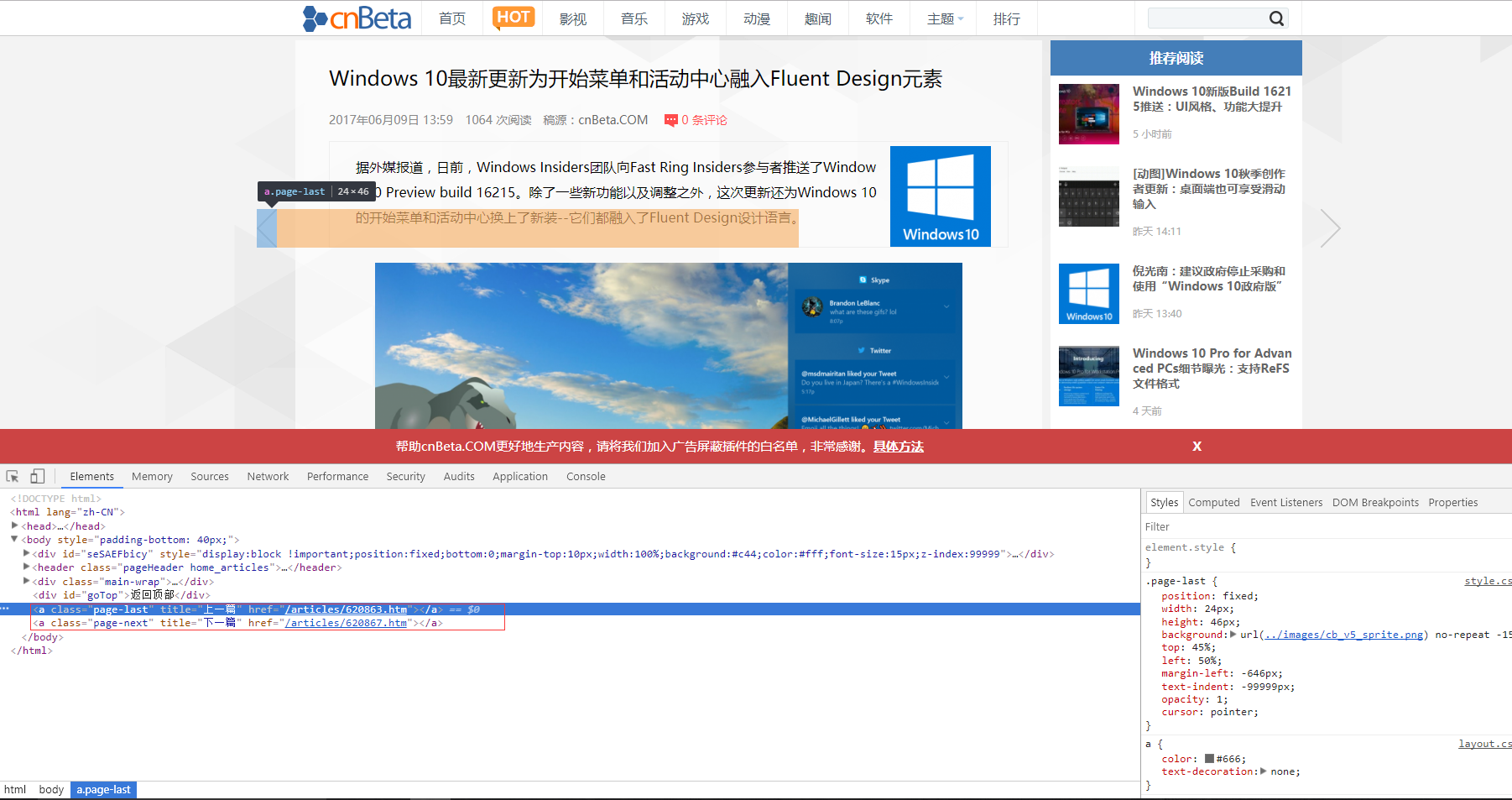
这是常见的防抓取措施,通过异步请求获取关联页面链接,再由js动态生成,查看网络面板可以看到页面确实发出了一个异步请求,结果中有我们要的关联页面ID:
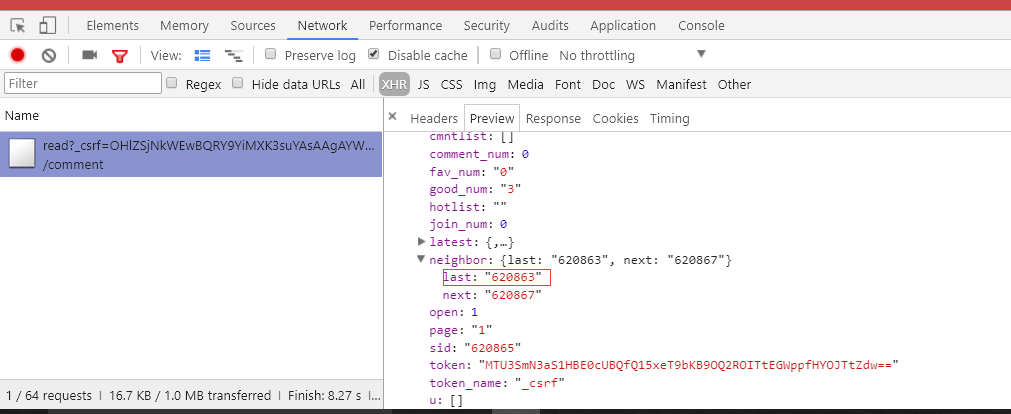
接下来分析这个请求,可以发现有两个参数,想必都可以从HTML中找到:
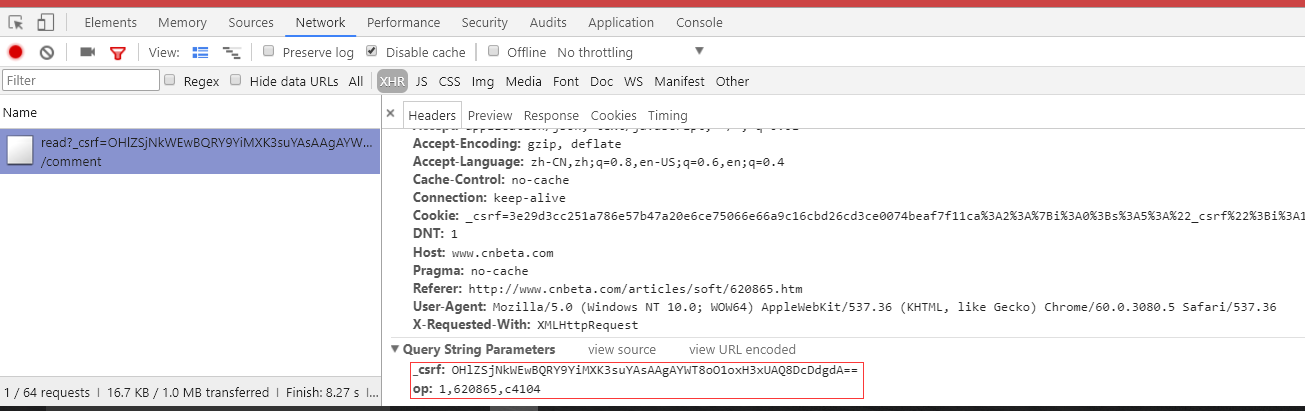
第一个参数_csrf很容易在源代码中直接搜索到了:

第二个参数全文检索找不到:
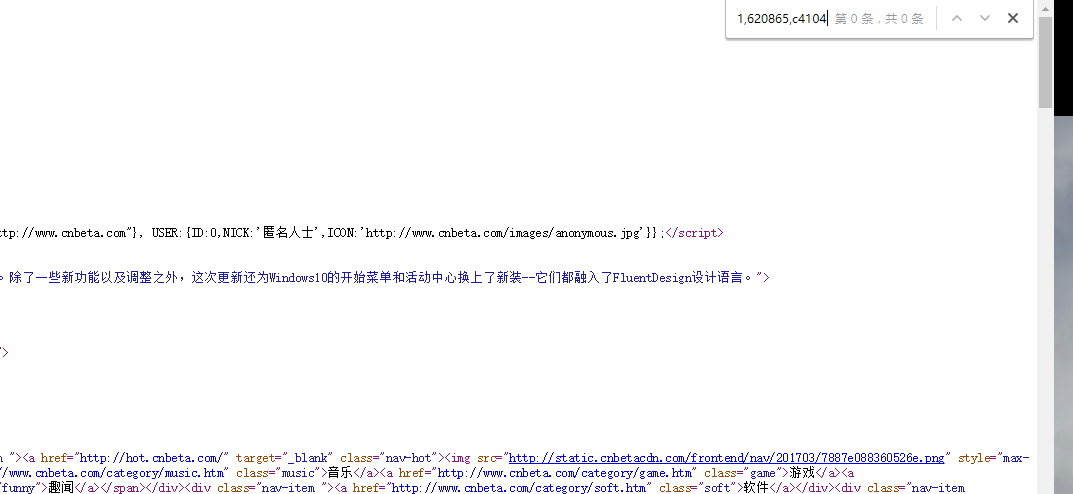
观察这个参数的结构,发现数据被两个逗号隔成三段,于是猜测数据是由于多部分拼接而来的,分开检索果然找到了:
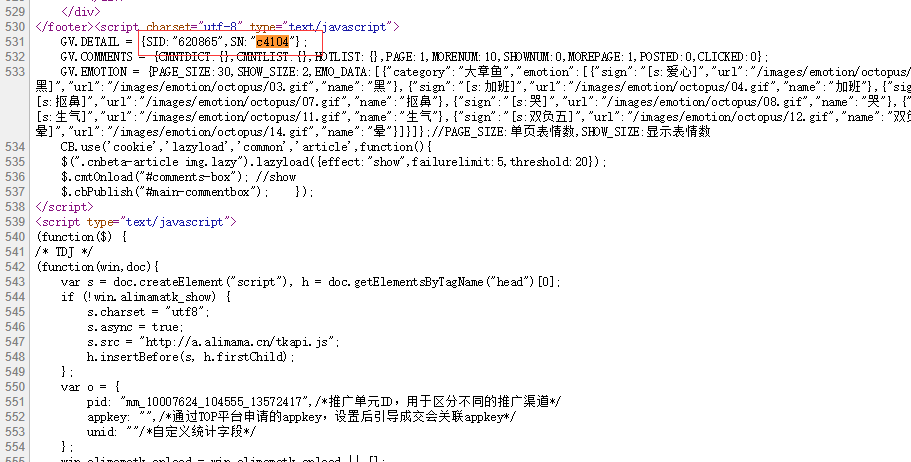
但只找到了数据的后两段,开头的1,不知道从哪来的,鉴于只有一个字符很难检索,而且观察发现很多页面中的这个请求都是1开头,所以这里干脆写死了。。。
至此对目标的分析就结束了,下面开始实现这个爬虫。
实现过程
程序结构
大致思路是,从起始页面开始抓取,异步获取上一篇新闻页面的链接继续抓取,设定最大抓取次数防止陷入死循环,伪码如下:
1 | let fetchLimit = 50; //最大抓取条数 |
功能点
重点是保存内容的实现,首先要获得页面HTML代码,主要用到http模块,如下:
1 | const http = require('http'); |
从HTML里获取信息可以使用正则匹配,或者使用cheerio,cheerio可以说实现了一个Nodejs端的jQuery,它跟jQuery的区别是需要先生成一个实例,然后的使用就跟jQuery一样了:
1 | const cheerio = require('cheerio'); |
保存文件主要使用fs模块,如下:
1 | const fs = require('fs'); |
这里有一个坑,我们希望将文章正文保存成与标题同名的txt文本,但标题中可能包含斜杠(/),当保存这样的文件时程序会将标题斜杠前的部分误认为成一个路径,从而报错,所以需要将标题中的斜杠替换掉。
保存图片跟保存文本大致相同,区别主要是写入格式,需要使用二进制方式写入:
1 | http.get(img_src, function(res) { |
程序的结构和主要功能点基本就是这样。
后记
实现一个爬虫说起来很简单,但健壮性真的很难保证,在爬取cnBeta过程中就发现另一个301跳转的坑,url发生跳转时程序捕获的HTML是空的,无法拿到真正的内容,所以在请求响应后还需要判断响应头是否是301,如果是就要从响应信息中找到跳转后的url重新发起请求。幸亏cnBeta不需要用户登录,如果是一个必须登录才能访问的站点,抓取会麻烦很多。
本项目的完整代码见 Nodejs crawler,感谢cnBeta^ ^。